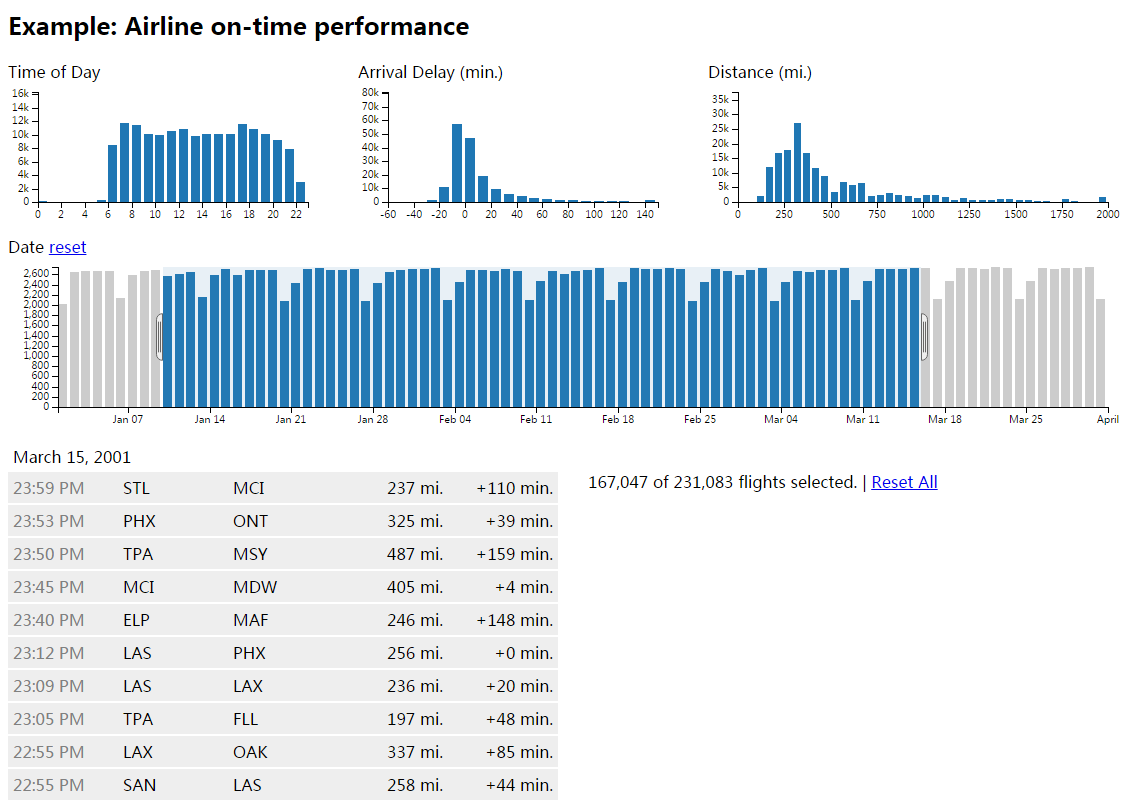
数据开发工作中,从上游消息队列抽取数据是一项常规的 ETL 流程。在基于 Hadoop 构建的数据仓库体系中,我们通常会使用 Flume 将事件日志从 Kafka 抽取到 HDFS,然后针对其开发 MapReduce 脚本,或直接创建以时间分区的 Hive 外部表。这项流程中的关键一环是提取日志中的事件时间,因为实时数据通常会包含延迟,且在系统临时宕机的情况下,我们需要追回遗漏的数据,因而使用的时间戳必须是事件产生的时间。Flume 提供的诸多工具能帮助我们非常便捷地实现这一点。
HDFS Sink 和时间戳头信息
以下是一个基本的 HDFS Sink 配置:
1 | a1.sinks = k1 |
%Y%m%d 是该 Sink 支持的时间占位符,它会使用头信息中 timestamp 的值来替换这些占位符。HDFS Sink 还提供了 hdfs.useLocalTimeStamp 选项,直接使用当前系统时间来替换时间占位符,但这并不是我们想要达到的目的。
我们还可以使用 Hive Sink 直接将事件日志导入成 Hive 表,它能直接和 Hive 元数据库通信,自动创建表分区,并支持分隔符分隔和 JSON 两种序列化形式。当然,它同样需要一个 timestamp 头信息。不过,我们没有选择 Hive Sink,主要出于以下原因:
- 它不支持正则表达式,因此我们无法从类似访问日志这样的数据格式中提取字段列表;
- 它所提取的字段列表是根据 Hive 表信息产生的。假设上游数据源在 JSON 日志中加入了新的键值,直至我们主动更新 Hive 元信息,这些新增字段将被直接丢弃。对于数据仓库来说,完整保存原始数据是很有必要的。